

This is the fifth post in our How to Conduct an SEO Audit in 2020 series. If you’re just joining us, we recommend starting at the introductory post.
Often people will overlook the technical factors that impact SEO. If you’re following along and conducting this audit in 2020 and beyond, you need to take them into account so the rest of your hard work isn’t impacted negatively.
It’s not uncommon to see a site or organization that’s spent lots of time and money in developing a strong SEO strategy only to have their strategy fail to perform due to abysmal site performance, keyword cannibalization, or poor site indexing.
Most of the technical factors we’ll discuss are not new to SEO strategy, but there are some that the SEO community has been anticipating will have - and in some cases already do have - increased ranking signals going forward. Some of these, like SSL Certificates, are also starting to have an impact on user experience, too, after some recent changes to the most popular browsers.
You definitely don’t want your users seeing this in their search bar:
Make sure you set up your SSL so your users see this instead!

We’ll cover the most prevalent technical factors and give you the tools and information you need to fix any problems that you discover.
First on the list:
Website Performance: Does your site load quickly enough?
Users on the modern web are increasingly sensitive to long load times. According to research aggregated by HubSpot, almost half of all consumers expect pages to load in less than 2 seconds, and every 1 second of delay in page load time results in a 7% reduction of conversions.
Think about what losing 7% or even 14% of your annual conversions simply because of poor page performance!
But consider the positive: you can add that much to your bottom line just by making your website perform more efficiently to give your end-users a better experience.
So how do you know if your website is performing well? You can utilize tools like:
They all provide similar insights, but it’s good to run your site through a variety of different tools at different times of day, from different source connections, and across different browsers and devices to get an average picture of how performance varies and fluctuates across a spread of variables.
Below is an example of the GTMetrix results for connorwhitman.com:
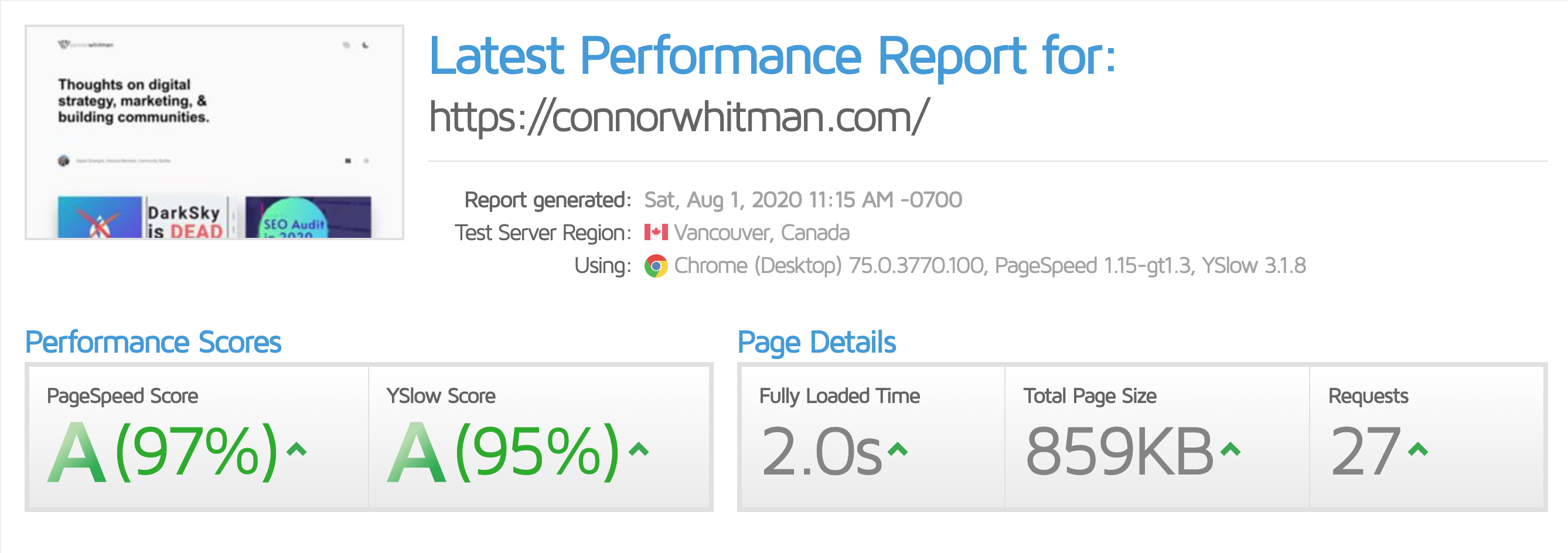
You can see the biggest key metrics to the right - the load time, overall page size, and number of requests.
Below the summary, you’ll see a tabbed list that goes into detailed performance insights ranked in descending order of quality.
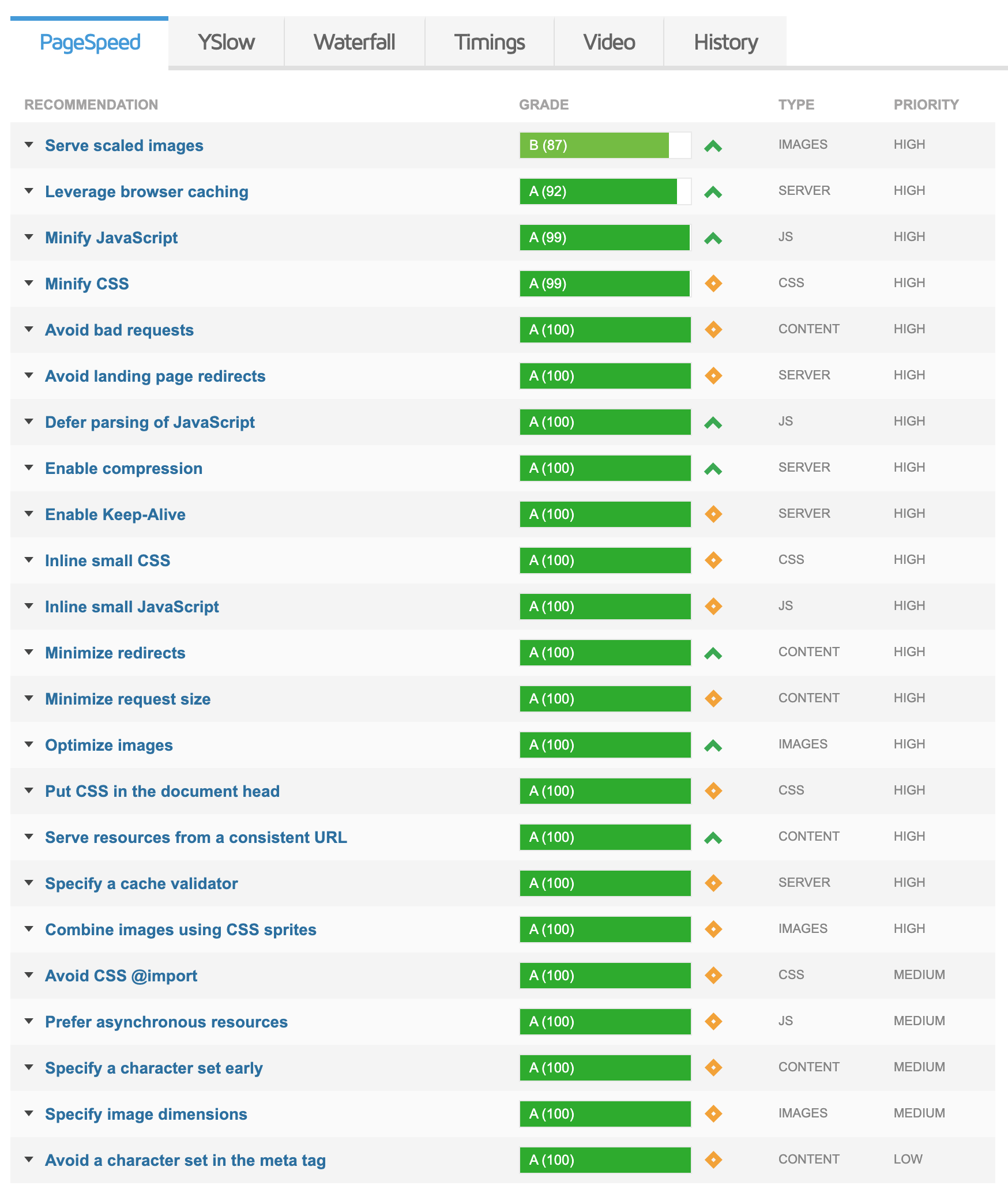
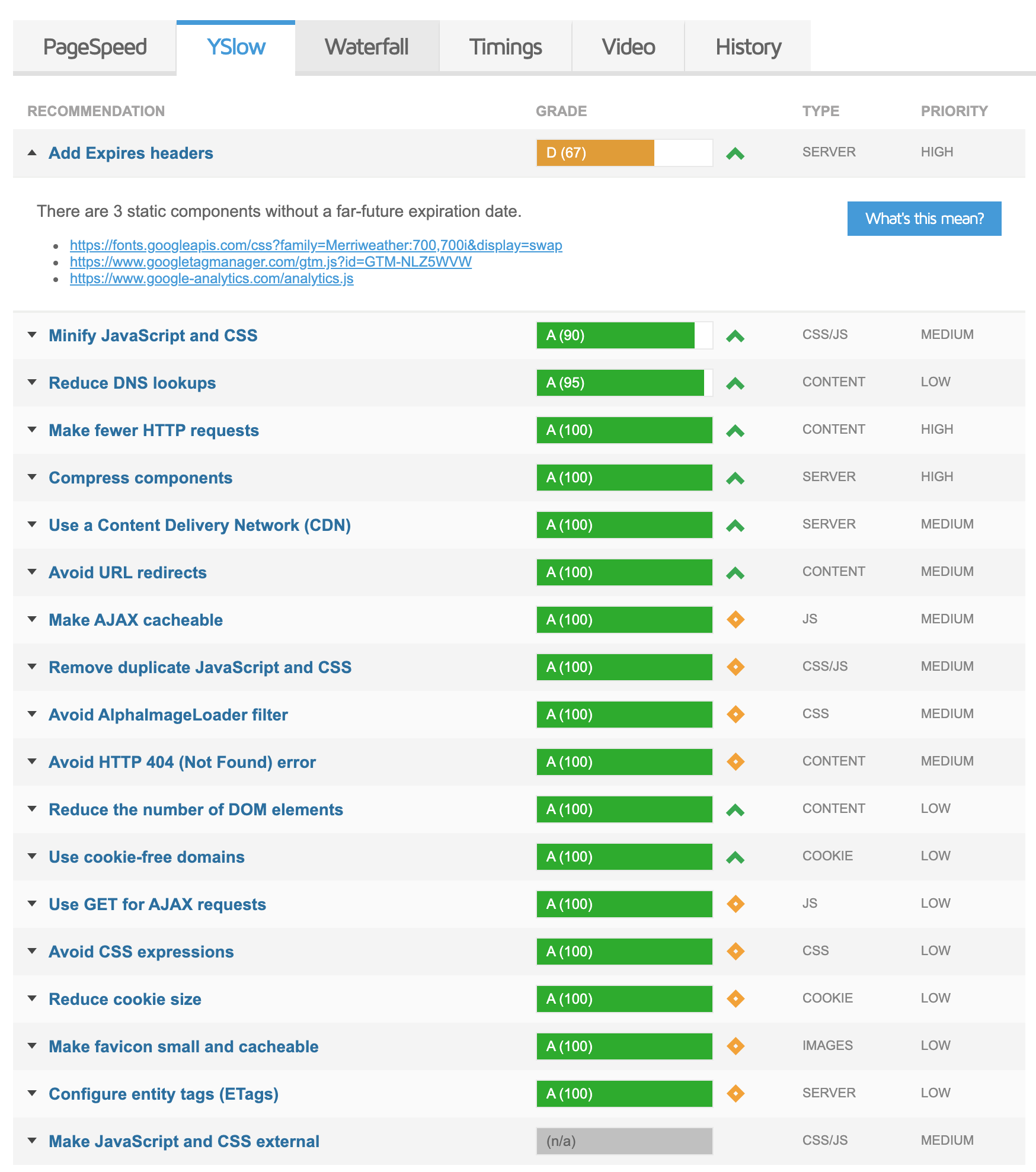
You may notice some lower scores on your site like we have on our YSlow analysis; be sure to look into them and examine the root cause.
In our case, we’re being told to add expires headers to some third-party resources: Google Fonts and Analytics! You might also see other external resources such as embed scripts from TypeKit and HubSpot; we don’t have control over those, and while we could store and serve a local copy, the maintenance overhead to keep that up-to-date - which keeps our analytics functioning - isn’t worth the incredibly small overhead. Also keep in mind that almost every user is going to have a cached version of the analytics script in their browser, so it won’t trigger another request.
If we continue to the Timings tab, we can see the most important metrics - how long it takes for the user to see the page and begin interacting with it. As we saw in our overview we hit the coveted two-second mark for the page fully loading, but this gives us a more detailed breakdown. With GTMetrix you can also watch recordings of your page loading.
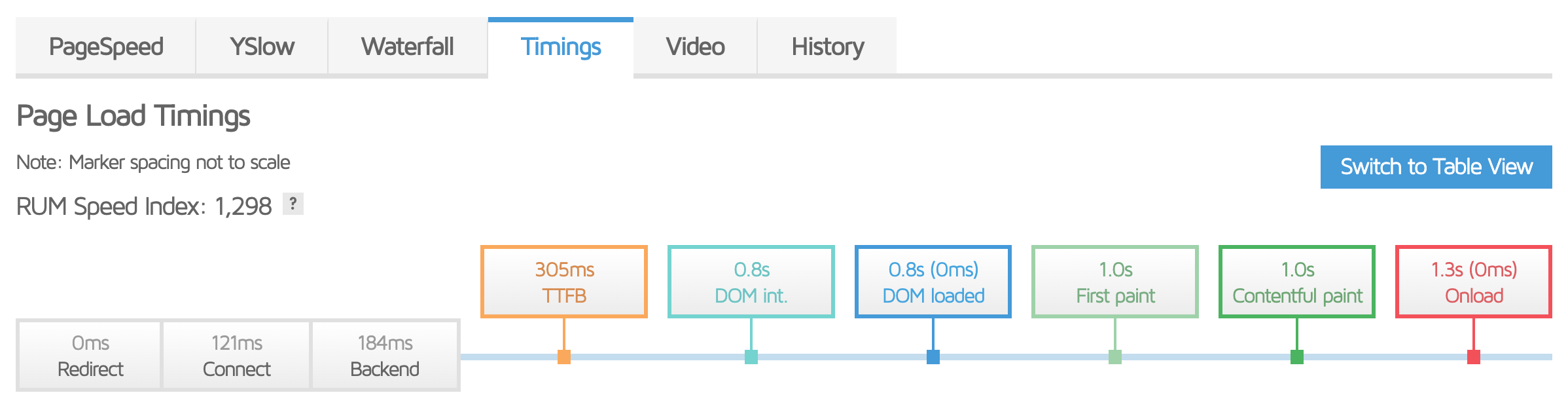
While we can’t cover every scenario or reason you may experience poor page performance, or how to fix them, this tool, and the others mentioned earlier, give you the ability to find problems and will point you to the resources and information you need to remedy them.
If you can get your load times under 1 second, you’re in firmly ahead of most of the competition on the internet, and anything 2 seconds and under is excellent!
Mobile Friendliness
The web has been moving firmly towards a mobile-first mindset for the last few years, and during your SEO audit, it’s the second most important technical factor behind page performance (in fact, it should be tied for first).
Like the site performance metric, the mobile friendliness of a site has a major impact on your business’s bottom line. A few major highlights from HubSpot’s 2017 marketing statistics research include:
- Over 33% of people accessing the internet use their mobile phone as their primary device
- Smartphone users are expected to nearly triple in the next three years
- Over 82% of mobile users research purchases they’re about to make in stores
- More than half of consumers make purchase decisions immediately or within an hour of researching a product on mobile
- Since mid-2015, Google has considered mobile-friendliness to be a strong ranking factor.
Without a mobile-friendly site, you will lose leads, customers, and ultimately business in two ways: As your search engine rankings decrease, fewer people will visit your site, and those that do will leave and look elsewhere.
If your site doesn’t provide your customers a quality experience on their device, they will look elsewhere.
Site performance and a mobile-friendly design are key to making a good first impression on your buyers and are the first step to helping them begin their buyer’s journey and to winning their business.
Now we often get asked, “well, how do I make my site mobile-friendly?”
The answer is relatively simple: If you know how to do it yourself, do it! If you don’t, then it’s time to talk to your friendly neighborhood developer.
There is, unfortunately, no button you can push to magically turn your website into one that will work with phones, so If your site isn’t mobile-friendly, though, it’s probably time for a full overhaul. (But I’d look at that as an opportunity!)
Keyword Cannibalization
Now we’ve discussed keywords and keyword strategy in a previous article, but there are some specific factors that are important to look out for and avoid.
One of these is known as “keyword cannibalization.”
What is “Keyword Cannibalization”?
This term refers to when two of your own pages are essentially competing for the same keyword. This can confuse search engine crawlers by forcing them to choose the “best” page for a given keyword or set of keywords.
Always keep in mind that while search engines - especially Google - have become incredibly intelligent due to their ever-evolving algorithms, they’re still computer programs and operate on a set of established rules.
While this can make SEO tricky in some ways, it also means you can guide the search engines specifically instead of hoping it makes the best decision for you.
We’ve mentioned focusing your efforts globally for your business on a small subset of keywords. The same principle applies to avoiding keyword cannibalization: focus and specificity.
If you have multiple pages optimized for a keyword then you’re essentially competing against yourself and spreading your efforts thin instead of focusing your efforts on one piece to give it the best chance you can to compete for the top spot on Google.
How to fix Keyword Cannibalization
Whether you’re building a new site from scratch or you’re running an SEO audit on an existing site, your first step should be to create a spreadsheet that will help you map out your site.
This should include the page title, it’s canonical URL, meta title, meta description, content length, ALT tags for images, any internal and external links and their anchor text, and the date of the audit.
This will help you visualize and organize how your site is viewed by search engines and will serve as a fantastic tool you can use to identify areas where you have overlapping keyword targets.
Once you identify the problem areas, you can determine if you can eliminate cannibalistic pages, concatenate them into one page for a given keyword, or re-write a page to focus on a separate keyword that isn’t currently a strong focus.
Easy Fixes and Common Problems
Some very common and easy-to-fix areas keyword cannibalization occurs is in the meta title and meta description tags. Don’t be lazy when writing these - make sure they’re well-written and relevant to the content on the page.
Another common area this occurs is on location and product description pages.
If you run a business that has multiple locations or serves multiple areas, you may be tempted to replicate one page and just change a few choice words like the address, area name, and other location-specific information. This is bad for two related reasons.
One, you’re generating duplicate content, which is something Google really hates.
Secondly, you may inadvertently be creating what are known as ”Doorway Pages.” These are bad because they’re against Google’s quality guidelines - another thing that will hurt your SERP rankings.
With regards to product descriptions, you’ll want to ensure your CMS and eCommerce platform aren’t generating a separate URL and page for each sub-type of your products.
For example, if you sell t-shirts on your store, you only want one page for t-shirts, not a separate page for each color t-shirt that you sell.
Most CMSes and eCommerce platforms can provide this functionality, but some will require more technical know-how than others.
Problems with Redirects
This section may be a bit foreign to anyone who hasn’t dealt with SEO and web development before, but we promise it’s easy once you understand the terminology!
We aren’t going to dive into the complexities of how the internet serves web pages to users, but we will cover a high-level overview of a relevant portion.
When you type in a URL, your browser takes you through a chain of web servers. If everything goes well, you end up at your destination and you’re served what you’re looking for!
In some cases, however, you’ll arrive at your destination and either the wrong thing is there, or nothing is. At this point, one of two things will happen.
In the good scenario, the owner of the property has put up a big sign that says “Hey! We know what you’re looking for, we moved that here!” Your browser then says “okay!” and takes you to what you were looking for. This is known as a 301-permanent redirect.
In the bad scenario, there may be no redirect, in which case you’ll probably end up at a 404-error page, a non-permanent redirect (302), it make take you down a redirect chain, or it may take you to a non-preferred version of the domain.
These negative redirect scenarios are the ones that you want to avoid for both user experience and for SEO.
To itemize, you will want to locate and fix any of these problems:
- No redirects in place resulting in a 404 error or serving the wrong content
- 302 temporary redirects
- Redirect chains
- Non-preferred URL versions not redirecting to preferred URLs
No Redirect: 404s and Incorrect Content
Google Webmaster Tools will let you know about 404 errors, so you can use that tool to track down any problem links and point them towards the right resource or remove them entirely if they’re now irrelevant.
You’ll have to do a bit more legwork for links that point towards incorrect content. You may be able to figure out some problem areas by looking at anchor text compared to the URL it points at, but this will require a manual evaluation.
In either case, though, the solution is the same: fix where the link points, or eliminate it.
302 Temporary Redirects
As the name explains, a 302 redirect marks a temporary page change.
While there are uses for this type of redirect, such as A/B testing, it does not pass page authority to the new page.
301 redirects indicate to search engines that the page has moved permanently, and as such all authority from the old page should be assigned to the new one.
In order to find 302 redirects, you can use a tool like Screaming Frog SEO Spider to batch process your site.
If you want a free option you can use the MozBar toolbar or Chrome’s Developer Tools.
All of these analyze the traffic path and will show you any redirects.
Once you’ve identified your 302 redirects you’ll want to shift them over to 301 redirects. The procedure to do this will differ depending on your web server and CMS.
We can’t cover all possible combinations and solutions, but unless your CMS has a feature or plugin that can facilitate implementing properly executed 301 redirects, you’ll need to edit your web server’s configuration. On Apache, this will be your .htaccess file, and on NGINX it will be either the nginx.conf file or the your-site-name.conf file under in the sites-available subdirectory.
If this doesn’t make sense to you or isn’t something you’re comfortable with, you’ll definitely want to talk to your server admin and/or your developer. Messing with these files can break your entire site and make it inaccessible to anyone.
Redirect Chains
You may have seen an error in your browser at one point that has said “This webpage has a redirect loop” and wouldn’t load the page.
This is an extreme example of a redirect chain.
Essentially what is happening is there is a series of URLs that redirect over and over. When you have Page A redirecting to Page B, which in turn redirects to Page C - and so on - you’re only passing partial authority to the final page.
The usual reason redirect chains occur is typically just the evolution of a site over time. At one point a 301 was set up from A to B. Time passes and Page C is now the preferred page, but there are links to Page B, so a 301 from B to C is set up. Many people forget to change the original redirect from Page A because no one’s thought about it in years, so it goes unnoticed.
Luckily, the fix is simple!
All you need to do is change the 301 redirect from Page A to point at Page C.
This way, the *full page authority from the two old pages is passed completely to the current, correct page.
As with changing 302s to 301s, ensure you know what you’re doing. Otherwise you need to contact your server admin or developer.
Preferred URLs
Once upon a time, you needed to type in www before the domain in order to access the public-facing website you were trying to reach. Nowadays that’s not the case, but the www. is still treated as a separate subdomain from the non-www domain.
In the eyes of search engines, www.example.com is different than example.com.
Whichever you choose has no effect other than the look of your URL, but it’s vital to ensure that your non-preferred URL has a 301 redirect to your preferred URL.
If you don’t do this, you end up with to identical websites that are both being indexed. As you can guess, this is bad. This is like keyword cannibalization on steroids, and on top of that you will end up losing rank for having duplicate content - something Google frowns heavily upon.
The other issue you may encounter is ensuring that your regular HTTP (non-secure) site is redirecting to your HTTPS (secure) URL. Not doing this has a similar impact to the www/non-www issue, but it also will impact your SERP rankings since having an SSL certificate for a secure-HTTPS site is a ranking factor.
The solution is the same: make sure that any HTTP URLs have a 301 redirect to their HTTPS counterparts.
You can use the previously mentioned tools to check for the proper redirects.
The same cautions about implementing 301 redirects apply.
One note about SSL certificates: make sure to get a certificate for both your preferred and non-preferred domain.
Site Indexing
If your site isn’t being indexed, or if it’s not being indexed well, you’re going to have problems with users finding your site organically!
There are two main areas you’ll need to focus on:
- Your
robots.txtfile - Your sitemap(s)
robots.txt
First, we’ll talk about robots.txt. This is essentially a permissions list for what search engine crawlers can and cannot look at in your site’s file structure.
This file should be located in your site’s root directory.
There are four main components you should see in this file:
User-agentDisallowAllowSitemap
User-agent is used to differentiate the crawlers for different search engines, i.e. Google or Bing.
Sitemap is used to tell the crawler where your sitemaps are located on your web server.
These two aren’t something the average user needs to worry about right off the bat.
The other two - Disallow and Allow are very important.
Disallow tells the crawler which directories it should NOT look at and index. You usually want to set this to exclude the folders that help run your CMS or contain any areas of the site that you don’t want indexed and visible on SERPs.
Allow does the opposite - it explicitly says that a crawler can index a specific file or folder. This is primarily used to allow a necessary subfile or subfolder that’s contained in a directory that has been disallowed.
The biggest thing to look out for is the following line: Disallow: /. This directive tells the search engines to disallow indexing of your entire website, which no one wants!
Sitemaps
Sitemaps tell search engine crawlers what pages exist on your site and help with accelerating the indexing of all your content, so you definitely want to have one!
Many CMSes will automatically generate one and keep it updated for you.
Once you have your sitemap, usually sitemap.xml found in the root directory for your site, you’ll want to submit it to Google Webmaster Tools.
You just want to ensure that this file exists, is up-to-date, and submitted to GWT. Other than that there’s nothing else you need to worry about!
Next, we’ll be diving into how to audit your on-page SEO.

